An index can be created in a table to find data more quickly and efficiently. The users cannot see the indexes, they are just used to speed up searches/queries.
Indexes are objects in the database that provide a mapping of all the values in a table column, along with the ROWID(s) for all rows in the table that contain that value for the column. A ROWID is a unique identifier for a row in an Oracle database table. Indexes have multiple uses on the Oracle database. Indexes can be used to ensure uniqueness on a database, and they can also boost performance when you’re searching for records in a table. Indexes are used by the Oracle Server to speed up the retrieval of rows by using a pointer. The improvement in performance is gained when the search criteria for data in a table include a reference to the indexed column or columns.
In Oracle, indexes can be created on any column in a table except for columns of the LONG datatype. Especially on large tables, indexes make the difference between an application that drags its heels and an application that runs with efficiency. However, many performance considerations must be weighed before you make the decision to create an index.
Note: Updating a table with indexes takes more time than updating a table without (because the indexes also need an update). So you should only create indexes on columns (and tables) that will be frequently searched against.
B-tree Index Structure
The traditional index in the Oracle database is based on a highly advanced algorithm for sorting data called a B-tree. A B-tree contains data placed in layered, branching order, from top to bottom, resembling an upside-down tree. The midpoint of the entire list is placed at the top of the “tree” and is called the root node. The midpoints of each half of the remaining two lists are placed at the next level, and so on
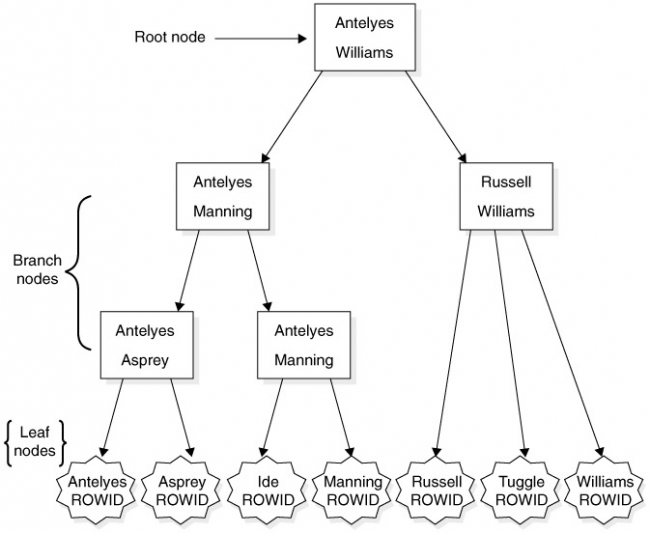
By using a divide-and-conquer method for structuring and searching for data, the values of a column are only a few hops away on the tree, rather than several thousand sequential reads through the list away. However, traditional indexes work best when many distinct values are in the column or when the column is unique.
The algorithm works as follows:
1. Compare the given value to the value in the halfway point of the list. If the value at hand is greater, discard the lower half of the list. If the value at hand is less, discard the upper half of the list.
2. Repeat step 1 for the remaining part of the list until a value is found or the list exhausted.
Along with the data values of a column, each individual node of an index also stores a piece of information about the column value’s row location on disk. This crucial piece of lookup data is called a ROWID. The ROWID for the column value points Oracle directly to the disk location of the table row corresponding to the column value. A ROWID identifies the location of a row in a data block in the datafile on disk. With this information, Oracle can then find all the data associated with the row in the table.
Tip: The ROWID for a table is an address for the row on disk. With the ROWID, Oracle can find the data on disk rapidly.
Bitmap Index Structure
This topic is pretty advanced, so consider yourself forewarned. The other type of index available in Oracle is the bitmap index. Try to conceptualize a bitmap index as being a sophisticated lookup table, having rows that correspond to all unique data values in the column being indexed. Therefore, if the indexed column contains only three distinct values, the bitmap index can be visualized as containing three rows. Each row in a bitmap index contains four columns. The first column contains the unique value for the column being indexed. The next column contains the start ROWID for all rows in the table. The third column in the bitmap index contains the end ROWID for all rows in the table. The last column contains a bitmap pattern, in which every row in the table will have one bit. Therefore, if the table being indexed contains 1,000 rows, this last column of the bitmap index will have 1,000 corresponding bits in this last column of the bitmap index. Each bit in the bitmap index will be set to 0 (off) or 1 (on), depending on whether the corresponding row in the table has that distinct value for the column. In other words, if the value in the indexed column for that row matches this unique value, the bit is set to 1; otherwise, the bit is set to 0. Figure 7-2 displays a pictorial representation of a bitmap index containing three distinct values.
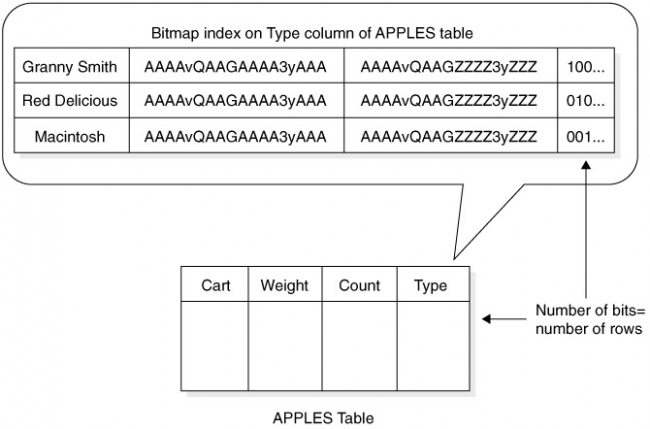
Each row in the table being indexed adds only a bit to the size of the bitmap pattern column for the bitmap index, so growth of the table won’t affect the size of the bitmap index too much. However, each distinct value adds another row to the bitmap index, which adds another entire bitmap pattern with one bit for each row in the table. Be careful about adding distinct values to a column with a bitmap index, because these indexes work better when few distinct values are allowed for a column. The classic example of using a bitmap index is where you want to query a table containing employees based on a GENDER column, indicating whether the employee is male or female. This information rarely changes about a person, and only two distinct possibilities, so a traditional B-tree index is not useful in this case. However, this is exactly the condition where a bitmap index would aid performance. Therefore, the bitmap index improves performance in situations where traditional indexes are not useful, and vice versa.
Tip : Up to 32 columns from one table can be included in a single B-tree index on that table, whereas a bitmap index can include a maximum of 30 columns from the table.
CREATE INDEX
You can create a unique B-tree index on a column manually by using the create index name on table (column) statement containing the unique keyword. This process is the manual equivalent of creating a unique or primary key constraint on a table. (Remember, unique indexes are created automatically in support of those constraints.)
Creates an index on a table. Duplicate values are allowed:
CREATE INDEX index_name
ON table_name (column_name)
Creates a unique index on a table. Duplicate values are not allowed:
CREATE UNIQUE INDEX index_name
ON table_name (column_name)
Creating Function-Based Indexes
To create a function-based index in your own schema on your own table, you must have the CREATE INDEX and QUERY REWRITE system privileges. To create the index in another schema or on another schema’s table, you must have the CREATE ANY INDEX and GLOBAL QUERY REWRITE privileges. The table owner must also have the EXECUTE object privilege on the functions used in the function-based index.
The function-based index is a new type of index in Oracle that is designed to improve query performance by making it possible to define an index that works when your where clause contains operations on columns. Traditional B-tree indexes won’t be used when your where clause contains columns that participate in functions or operations. For example, suppose you have table EMP with four columns: EMPID, LASTNAME, FIRSTNAME, and SALARY. The SALARY column has a B-tree index on it. However, if you issue the select * from EMP where (SALARY*1.08) > 63000 statement, the RDBMS will ignore the index, performing a full table scan instead. Function-based indexes are designed to be used in situations like this one, where your SQL statements contain such operations in their where clauses. The following code block shows a function-based index defined:
SQL> CREATE INDEX ixd_emp_01
2 ON emp(SAL*1.08);
By using function-based indexes like this one, you can optimize the performance of queries containing function operations on columns in the where clause, like the query shown previously. As long as the function you specify is repeatable, you can create a function-based index around i
DROP Indexes
When an index is no longer needed in the database, the developer can remove it with the drop index command. Once an index is dropped, it will no longer improve performance on searches using the column or columns contained in the index. No mention of that index will appear in the data dictionary any more either. You cannot drop the index that is used for a primary key.
The syntax for the drop index statement is the same, regardless of the type of index being dropped (unique, bitmap, or B-tree). If you want to rework the index in any way, you must first drop the old index and then create the new one. The following is an example:
DROP INDEX employee_last_first_indx_01;
Recent Comments